
About ·
Web Size ·
Web Servers ·
History ·
Research ·
How it Works ·
The Team ·
Contacting Us
About WebCrawler
The WebCrawler is a web robot. It is the first product of an experiment in information discovery on the Web. I wrote it because I could never find information when I wanted it and because I do not have time to follow endless links.
The WebCrawler has three different functions:
- It builds indices for documents it finds on the Web. The broad,
content-based index is available for searching.
- It acts as an agent, searching for documents of particular interest to the user. In doing so, it draws upon the knowledge accumulated in its index and some simple strategies to bias the search toward interesting material. In this sense, it is a lot like the Fish search, although it operates network-wide.
- It is a testbed for experimenting with Web search strategies. It is easy to plug in a new search strategy, or ask queries from afar, using a special protocol.
In addition, the WebCrawler can answer some fun queries. Because it models the world using a flexible, OO approach, the actual graph structure of the Web is available for queries. This allows you, for instance, to find out which sites reference a particular page. It also lets me construct the
Web Top 25 List,
the list of the most frequently referenced documents that the WebCrawler as found.
How it Works
The WebCrawler works by starting with a known set of documents (even if it is just one), identifying new places to explore by looking at the outbound links from that document, and then visiting those links.
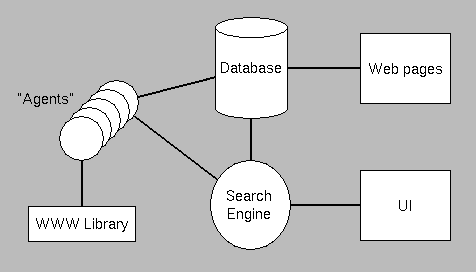
It is composed of three essential pieces:
- The search engine is responsible for directing the search, either using a general
breadth-first search strategy or a more directed "find-me-what-I-want" stategy.
In a breadth-first search, it is responsible for identifying new places to visit by looking at the oldest unvisited links from documents in the database. In the directed search mode, the search engine directs the search by finding the most relevant places to visit next.
- The database contains a list of all documents, both visited and unvisited, and an index on the content of visited documents. Each document points to a particular host and, if visited, contains a list of pointers to other documents (links).
- "Agents" retrieve documents. They use CERN's WWW library to retrieve a specific URL, then return that document to the database for indexing and storage. The WebCrawler typically runs with five to ten agents at once.
Being a Good Citizen
The WebCrawler tries hard to be a good citizen. Its main approach involves the order in which it searches the Web. Some web robots have been known to operate in a depth-first fashion, retrieving file after file from a single site. This kind of traversal is bad. The WebCrawler searches the Web in a breadth-first fashion. When building its index of the Web, the WebCrawler will access a site at most a few times a day.
When the WebCrawler is searching for something more specific, its search may narrow to a relevant set of documents at a particular site. When this happens, the WebCrawler limits its search speed to one document per minute and sets a ceiling on the number of documents that can be retrieved from the host before query results are reported to the user. The WebCrawler also adopts several of the techniques mentioned in the
Guidelines for Robot Writers.
Implementation Status
The WebCrawler is written in C and Objective-C for NEXTSTEP. It uses the WWW library from CERN, with several changes to make automation easier.
Search ·
Help ·
Facts ·
Top 25 Sites ·
Submit URLs ·
Random Links ·
No-forms Search
 Copyright © 1995, America Online, Inc.
Copyright © 1995, America Online, Inc.
info@webcrawler.com