
 Perl Magic
Perl MagicLast month we introduced the Virtual Press Room (vpr), a World Wide Web application that organizes the press releases that pile up in BYTE editors' offices. This month we'll look more closely at how vpr works, focusing on two important techniques: using hidden fields to transmit user input through a series of forms, and building Lotus Notes-like views of a Hypertext Markup Language (HTML) archive.
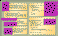
The vpr system (see the figure "Inside the Virtual Press Room") comprises three kinds of files: hand-written HTML documents, Perl-generated HTML documents, and Perl scripts. As is typical of Web applications, vpr documents call scripts, which call library routines, which write other documents, which call other scripts and library routines, which write other documents. It's gnarly, but it works.
It's also supremely portable. Browsers on any platform can use vpr. I've also run the vpr back-end scripts on the National Center for Supercomputing Applications (NCSA) Web server under BSD/OS, and on WebSite and the Netscape Commerce Server under Windows NT.
Gathering the Input
The Submit button on the opening vpr form calls the Common Gateway Interface (CGI) script vpr1.pl, which parses the input and produces one of three kinds of documents: a Required Changes page, an Optional Changes form, or a Preview form.
The Required Changes page lists errors. If there's an empty field, or one that contains more than the maximum amount of text, this page tells you to use your browser's go-back function to return to the input form and try again. Most browsers retain the state of that form, but some annoyingly do not -- a defect for which vpr does not yet compensate.
The Optional Changes form lists warnings -- for example, that there are HTML tags in the input. Why must there be no HTML? The vpr application wants to have control over the HTML formatting of the documents in its archive to ensure consistency of look and feel. Because vpr automatically transforms a uniform-resource-locator-signifying (URL) string (http://www.byte.com) into the corresponding HTML link (<a href="[unarchived-link]" href="http://web.archive.org/web/199603/http://www.byte.com>/">http://www.byte.com>;http://www.byte.com<;/a>), there's no need for vpr users to encode HTML back-links to their own sites.
What if you need to refer to HTML-like strings in a document? For example, a Sun Microsystems press release on Java might contain an example of the new <app> tag used to invoke Java applets. The vpr application will not reject input containing HTML. Instead, its Optional Changes form warns you that it found HTML in the input.
If you intend to use the HTML as text, fine. You can submit the form and go on to the preview. The vpr application will neutralize the HTML tag delimiters < and > by converting them into the entity references < and >. If you intend to use the HTML as code, too bad; vpr will flatten it anyway, so you might want to go back and remove it.
Finally, the Optional Changes form's action script, vpr3.pl, invokes a library function, &Preview, and passes in the form's data. The &Preview function writes another form that shows how the input will appear with the vpr-supplied background, icon, text formatting, and automatic hyperlink activation.
The First Path to the Preview
If vpr1.pl detects no required or optional changes, it calls &Preview directly. That means there are two paths to the preview form. One path runs this way: input form -> vpr1.pl -> &Preview . The other goes like this: input form -> vpr1.pl -> Optional Changes form -> vpr3.pl -> &Preview .
On the first path, vpr1.pl can use the standard Perl CGI library that's kicking around on the Internet (ftp://ftp.intergraph.com, ftp://www.process.com) to decode the form's data and transfer it into Perl variables.
But wait. Decode? The two methods that Web clients can use to send form data to servers -- GET and POST -- encode that data as a URL. GET works like an extended command line, calling the program and the name/value pairs with URL syntax that looks like this:
http://cgi-bin/vpr1.pl ?comp=byte&prod =Virtual+Press+Room
Here, ? means begin the list of pairs, = connects a name to its value, and + stands for a space.
In the POST version of this transaction, the data reaches vpr1.pl by way of standard input rather than via the command line. The vpr1.pl script, which accepts up to 5 KB of input, necessarily uses POST because you can't pass all that data on the command line.
Either way, the transmitting browser must protect the class of characters that have special meaning in URLs, including ?, /, <, and >. So, it encodes them like this: %3F, %2F, %3C, and %3E. The parser in the standard Perl CGI library knows how to decode this syntax.
Hiding Form Data
On the second path, vpr1.pl transmits the form's data to the Optional Changes form that it writes and that vpr3.pl handles. Users never even see this data, but vpr1.pl has to pass it to vpr3.pl so it in turn can pass it to &Preview . How does this work? The vpr1.pl script adds hidden fields to the Optional Changes form using Perl statements like this:
print "<input type=hidden name=company value=$company>";
This worked fine for simple fields but fell apart when I fed in whole press releases. These required another layer of encoding so that special characters in the text would not ruin the integrity of the form's hidden fields. And, of course, the new encoder needed a matching decoder.
Sound hairy? It's hard to think about (at least for me it is), but it's easy to do. Here's the encoder:
$s = equivalent s/($RE_SPECIAL)/"%" .
sprintf("%2.2lx",ord($1))/ge;
$s is a Perl string containing, say, the body of a press release. The =~ operator binds the search-and-replace operation to that string. The s/OLD/NEW/ge function searches for the regular expression between the first and second slashes and then replaces it with what's between the second and third slashes. The g modifier at the end of the encoder says, "replace all occurrences."
The e operator is truly magical. It says, "evaluate the replace string as a Perl expression and use the result of that evaluation for the replacement." $RE_SPECIAL is a string, such as "[\x22\x25]," that enumerates the special characters to be encoded. The ord function gives the ordinal value of $1, which stands for each character matched by $RE_SPECIAL. Finally, . concatenates a % with the hexadecimal-formatted output of sprintf.
Here's the decoder (lifted from the Perl CGI library):
$s = equivalent s/%(..)/pack("c",hex($1))/ge;
Here, %(..) matches strings such as %5C and %5E, and pack makes a character out of the corresponding hexadecimal value.
The vpr application employs hidden fields along with this coding/decoding scheme twice -- once when vpr1.pl writes the Optional Changes form, and again when &Preview writes the final preview form. To the user, it looks like a sequence of dialogues typical of a normal GUI application. To the programmer, it would be a nightmare without the magic of Perl.
Am I becoming a Perl nut? You bet. Life's short, and what can't get done in a day usually doesn't get done at all. Perl is to the Web what Visual Basic was to Windows programming -- a quick-start toolkit that a merely competent programmer (like me) can use to build a really useful application in one day.
Building Notes-Like Views
In the spirit of Lotus Notes, vpr offers multiple views of the press-release archive it manages -- by date, by company, and by product. Perl's powerful string-parsing, array-building, and array-sorting functions made it a snap to create multiple views of the database.
How do you structure an HTML document collection so it can act like a Notes database with multiple views? Here's one approach. Start with an HTML form. When you process the form's data (see "BOMB's Away," October BYTE, for a discussion of basic CGI programming using Perl), store the fields that will serve as sort keys in the header of the HTML document that you create.
The HTML <meta> tag, valid within a document's header, is a great place to tuck arbitrary name/value pairs that browsers won't touch but that other utilities can use. Here's an example:
<html><head>
<meta name=company value="BYTE">
<meta name=product value="Virtual
Press Room">
Then you parse the document and extract the key values into variables. Perl's split function makes this easy (see the figure "Data Views in Perl," parts A and E). Combine the keys once for each view and then add each combination to an array representing that view. Again, this is very easily accomplished (see part B). Sort the arrays (part C). Finally, walk through each array, split each item back into its component parts, and then write an ordered HTML table of contents (parts D and F).
As our archive grows from tens to hundreds of documents or more, it will become impractical to list each complete view in a single HTML document. Web browsers can't fetch parts of a document as needed; they have to grab the whole thing. Therefore, vpr also builds views that segment alphabetically (e.g., just the companies whose names begin with the letter M) as well as by date (e.g., just the announcements for August 1995). You see examples of this kind of segmentation all over the Web.
Eventually, I may need to slide a real database underneath vpr. But because Perl can rapidly slurp up and sort arrays of tens and even hundreds of thousands of items on a 32-MB Digital Equipment AXP 150, I'm happy to keep things light, flexible, and portable for now.
TOOLWATCH
Transparent GIF Page
(http://www.vrl.com/Imaging/transparent.html)
A transparent GIF is the Webmaster's equivalent of a printer's em space. Aim this Web utility at any GIF on your site that you want to make see-through, and it'll hand you back a GIF89a-format transparency.
BOOKNOTE
NetLaw: Your Rights in the On-Line World, by Lance Rose
Osborne/McGraw-Hill, 1995 ISBN 0-07-882077-4 Price $19.95
A lawyer's plain-spoken advice concerning on-line fraud, defamation, censorship, invasion of privacy, infringement of copyright, obscenity, and more. Serious users and operators of on-line systems should read and understand this vital handbook.
The vpr system rests on the twin pillars of Web programming: HTML and Perl. Some HTML documents are written by hand (a). Most documents (b) are written by Perl scripts (c).


 Copyright © 1994-1995
Copyright © 1994-1995