
R. P. Channing Rodgers Suresh Srinivasan Computer Science Branch Lister Hill National Center for Biomedical Communications National Library of Medicine National Institutes of Health Bethesda, Maryland 20894 USA
In the 1980s, LHNCBC undertook development of a laser videodisc compendium of the NLM's History of Medicine Division (HMD) prints and photographs collection. This collection includes over 59,000 fine prints, photographs, ephemera and posters. The collection was photographed on 35 mm film, and the images were transferred to laser videodisc. The videodisc was used as part of a PC-based image retrieval system, known by various names during its development (HARPP, Picquick), but currently named Images from the History of Medicine [2].
On-Line Images from the History of Medicine (OLI) was intended to provide Internet access to this image collection and its accompanying textual catalog.
The entire image collection requires about 2.3 GB of disk. Typically, a JPEG file is about 30 KB in size, and the corresponding GIF thumbnail is about 6 KB in size.
An ASCII file containing the full catalog information for the collection was extracted from dBase-III files on a CD-ROM created for the Picquick project.
Selecting a search by text expression produces a form such as that shown in Figure 1.
Figure 1. The form for searching by text expressions.
The original catalog contains many distinct fields; for indexing, fields of a similar nature have been collapsed into broad categories to enable a simple interface. The user performs field-restricted searches by entering search patterns in any of the windows labelled: Title/Abstract, Name Fields(s), and Start and End Year (for which radiobuttons allow the selection of B.C. or A.D.). Menu boxes allow selection of specific geographical locations throughout the world, or within the U.S. A text window labelled "Any Text Field" applies to any of the title, abstract, topical heading, or name fields.
Words appearing within a text window are implicitly joined by Boolean OR operations unless separated by the word and, in which case they are joined by a Boolean AND. Similarly, the geographical locations from the two selection lists are joined by Boolean ORs. Text expressions appearing within a given text window are, in effect, enclosed within parentheses and joined by a Boolean AND to the contents of any other non-empty text window. Text can also take advantage of suffix truncation (for example, nurs* matches nurse, nurses, nursing, nursery, etc.). Enclosing multiple words within a pair of double quotes causes them to be searched for as an intact multi-word phrase. Stop words are filtered from catalog entries prior to indexing, and thus should not be employed within phrases or as an operand of a Boolean AND, as this will preclude any matches.
After a search pattern is specified, the user indicates whether the pattern is to be used to produce a simple English-language explanation of how the pattern will be interpreted, or to perform a search. The action is then triggered by a submit button.
When a search is completed, a summary page is returned, showing elapsed clock time and the number of images found. Images are returned for examination in browsing subsets; the user indicates how many images to send back in each browsing subset. Browsing subsets contain thumbnail images and brief catalog extracts (including a headline, a brief textual description drawn from the title, subtitle, or abstract fields; see Figure 2). An image marked in the catalog as restricted (for example, due to copyright) is accessible only at authorized sites; at other sites, an explanatory image is displayed in its place. Clicking on an abbreviated description displays the corresponding full catalog entry, and clicking on a thumbnail displays a full-sized image (Figure 3). Special characters such as foreign accent marks are correctly mapped into their HTML encodings prior to display. An image may be marked by selecting the checkbox at the upper left-hand corner of the corresponding thumbnail; marked images may be retrieved as a new retrieval set. Facilities of the WWW client may be used to print any of the display screens.

Figure 2. A sample browsing page (only one image).
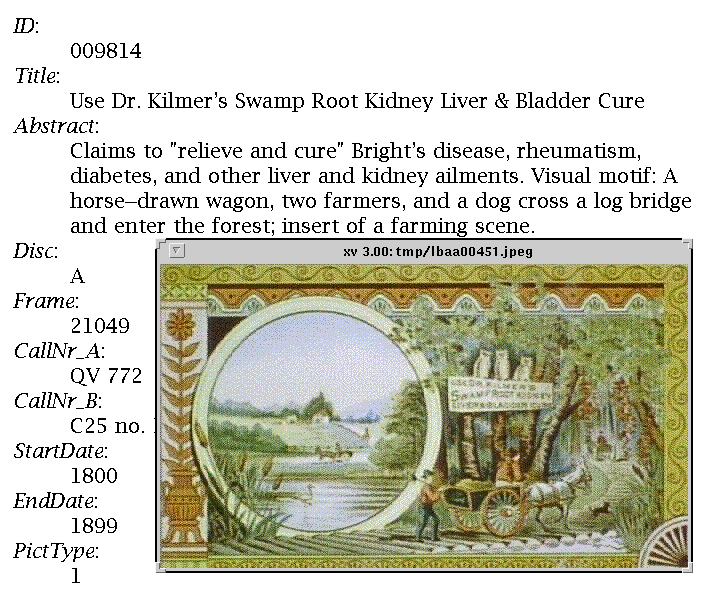
Figure 3. A full-sized version of the thumbnail image from Figure 2, superimposed on its complete catalog display.
The catalog contains some 500,000 non-unique words (where a word is defined as a run of two or more alphanumeric characters). A perl script extracts these words from the title, subtitle, abstract, and topical heading fields, and multiple fields containing personal and corporate names. The text search mechanism is implemented (external to POSTGRES) as a simple binary search of a sorted file to identify the words in the query. Prefix matching is also done at this stage by identifying all words with the given prefix. Memory mapping facilities considerably speed up these searches. A temporary Word class is then created and loaded with these words. Since this class contains only the words in the query, scans of this class for boolean operations, truncation, etc., are reasonably fast. Finally, suitably qualified POSTQUEL commands are generated for the search. In the POSTQUEL, truncation is handled as a range query. For example, the query kidney* generates: ...where w.word >= "kidney" and w.word < "kidnez". The upper limit on the range is automatically generated to be just greater than all the words with that prefix. Phrase searching is handled using word position information. The Word class has an attribute recording the position of the word in the catalog within a specific field. In a phrase, word positions must be consecutive and the words must all occur in the same field. Clearly, more sophisticated search mechanisms will be needed for a fully functional system.
The first non-empty field among the title, subtitle and abstract fields (in that order) forms the headline for the record. If all three fields are empty, the string "No title" is employed.
The field containing geographical information encodes the world region, the country and, for some countries like the U.S., state information. Not all records carry this information, however. These classes are not indexed and all searches on these classes (World, State) default to scans.
The time period referenced in the time field varies, but the lowest level of granularity is a decade and the highest, a century. Matches are found if the time range requested in the search intersects the period spanned by the image.
On the server end, nlmhmd stores the result set for each search. This contains the unique identifiers (UI's) of records matching a given query. Currently, each search is assigned a unique session UI. A separate file stores the mapping of session UI's to information about the client, such as the IP address, host name, last access time, etc. The program also maintains information about the subset of records that the user has marked. When the user requests the records that she has marked, the marked subset replaces the result set for that search.
The HyperText Transport Protocol (HTTP) underlying World-Wide Web is a stateless protocol, whereas a fully developed retrieval protocol such as Z39.50 maintains state to enable multiple sequential operations on a result set. OLI hides a state engine behind a stateless communications protocol. State information resides in files on the server and is also transmitted to the client in hidden fields within HTML+ forms. To this end, appropriate client support is critical. As of this writing, the only client supporting hidden fields within forms is NCSA Mosaic for X (version 2.2 or later). The result of a form submission is a POST query to the server. The CGI specifies how data from the client is passed to nlmhmd.
Hidden fields in forms encode state information that is used by nlmhmd to maintain context between communications with the server. They are used in the spirit of the slot/value notation where the names of the hidden fields are the slots and their contents are the values.
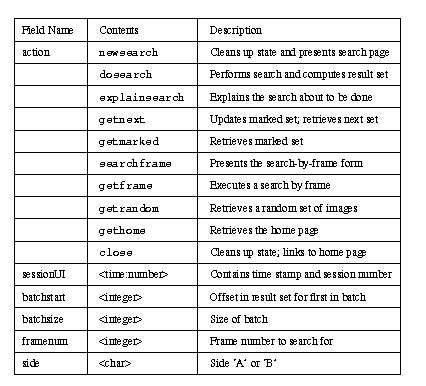
Table 1. Hidden Field Names and Contents
The hidden fields and their permissible contents appear in Table 1. The fields (slots) used are:
Nlmhmd parses the data that it receives via the CGI and performs the necessary action. The results are then packaged into an appropriate (dynamically generated) HTML page and returned to the client. A simplified state transition matrix for the program is shown in Table 2.
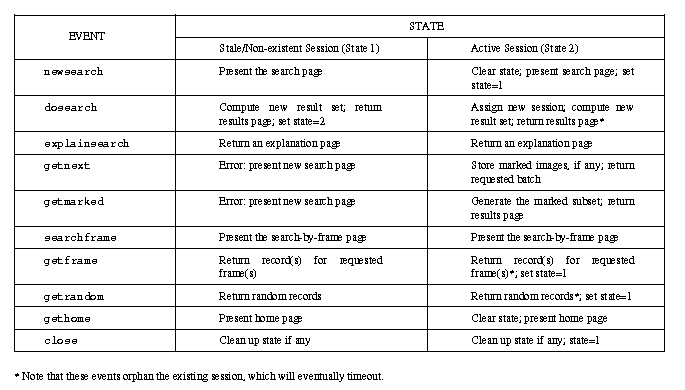
Table 2. State Transition Matrix
The On-Line Images Project is distinguished from earlier efforts at Internet-distributed image databases, such as the collection of solar magnetograms created by CNIDR, [5] by the size of its collection, the relative richness of its catalog structure, a fuller use of HTML+ forms capability, and by the increased sophistication of interactions which its state engine allows.
There are a number of improvements and additional features under development which will enhance the utility of OLI:
http://hostname/cgi-bin/mailform?recipient=emailaddr
(where hostname is the name of the server,
and emailaddr is the intended mail address).
Alternatively, the address can be embedded within a form
of the invoking application,
by setting the value of the hidden field named recipient to the
desired address.
[2] W. R. Leonard and J. R. Stokes, Proceedings, Interactive Videodisc in Education and Training, Twelfth Annual Conference, Society for Applied Learning Technology, August 22-24, 1990, p. 40-44, Washington, D.C., 1991.
[3] L. Wall, R. L. Schwartz, Programming perl, O'Reilly & Associates, Inc., Sebastopol. CA, 1990. (454 pages).
[4] S. Wensel, ed., "The POSTGRES Reference Manual," Report M88/20, Electronics Research Laboratory, University of California, Berkeley, CA, March 1988
[5] J. Fullton, "Distributed image archives,", Proceedings, Astronomical Data Analysis Software and Systems (ADASS), Victoria, British Columbia, Oct 1993, (in press, 1994). The Uniform Resource Locator (URL) for the CNIDR documentation is: http://cnidr.org/cnidr_papers/archives.html/; the service itself can be accessed at: http://argo.tuc.noao.edu/.
[6] B. L. Humphreys and D. A. B. Lindberg, "The UMLS project: making the conceptual connection between users and the information they need", Bulletin of the Medical Library Association, 81(2):170-177, 1993.