
This paragraph provides an overview of the technical environment in which the prototype of The COOPerator is build. We were limited by both the minimal configuration as well as the network infrastructure. The larger part of the contents of this page appeared earlier in Bosters et. al. [1995]
A major restriction on the implementation of the prototype is the fact that it should work in an educational setting and is meant to be used by students. This implies that the system should be able to run on simple machines that students can affort to have at home. Thus large unix systems, and high speed communications, are out of the question. Instead simple AT-class machines with low-speed modems and operating under MS-DOS® plus MS-Windows®. The choice for windows is mainly motivated by the fact that it provides some form of hardware independency. Besides it works reasonably well on small AT-class machines which represent a valid minimal configuration for using The COOPerator.
The use of the system can be roughly split into two ways. On the one hand, a student is merely using the editor to change his own parts of the group document or to make some private annotations. In this case, it will not be necessary to connect to any other machine. By using The COOPerator in any other way, a student will inevitably want to receive the latest contributions from his group members and send the latest changes he made to the shared environment. This notion leads to the following figure:
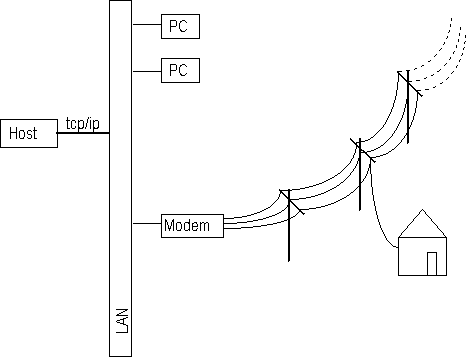
The synchronisation of personal data with that of the group is an important obstacle in a working environment that is characterised as asynchronous. It influences the amount of data that will have to be transmitted over the network. In this network there almost always will be slow telephone lines that incur great cost (due to the low-speed modems) and long delays if too much data has to be transmitted. Therefore, one of our basic assumptions is that any bit moving over the net is one bit to many. The network is given in the following figure, which is adapted from Bosters [1995]:
The common data space can be modelled using a scale from one extreme to the other. At one end all data is always stored at the central host and at the other end no data is ever stored at a central host but is always kept locally and is only available on demand. This leads to the next figure in which both the extremes and one intermediate solution are placed:

The following criteria were used to determine in which way the common data space would be implemented:
The second criterion is important with regard to the costs of communication. For example, using a LAN the costs remain nil, but when using telephone lines they go up with the amount of data that needs to be transmitted.
In a situation with a high frequency of changes in the common data space the method of choice is number one. This gives the ability to react swiftly to changes. The disadvantage is higher cost due to constant network load and the client-server approach.
Option three is suitable if the partners contact each other at a very infrequent basis. In this case, the common data space seldom changes. This low frequency then offsets the complexity of having to call everyone.
Like option three, the second option has the advantage of a low network load. Besides, the complexity of the system remains low because only one central host is needed to exchange the group's data. This would be a nice method to use in a situation of only fair update frequencies of the common data space.
Since this is the situation we expected The COOPerator to operate in, the second option was chosen. Furthermore, since a graph is used as the data-structure for the shared environment only lists of added nodes and edges (together with their contents) as well as a list of identifiers of nodes and edges which should be dropped have to be transferred. So the updates can be completely differential and this ensures that not a bit too much ever travels the network.


Sjoerd Michels, Tilburg, The Netherlands